Analysis is hard. You have to formulate a question, find the data that purports to answer that question, slice and dice the data into something manageable, then maybe, just maybe, you’ll answer the question at hand. Oh, but if you mess something up or don’t answer the question, you get to go through the whole process again. Ugh.
Some of those steps are specific to the analysis and are opportunities to provide contextual insights and value to the end user … such as formulating the right question and interpreting the results. Others, like slicing and dicing, are less intrinsically valuable, however necessary toward the end goal.
One of our goals is to reduce the effort of the menial tasks in analytics, like data manipulation. One area of data manipulation is aggregation, and that’s what this post focuses on, or put another way, how to make groupings cleaner.
Group Bys Gone Wrong
A common task in analytics is the standard “GROUP BY”. This might be something like sum the impressions and group by channel.
If everything goes well, you’d end up something like this:
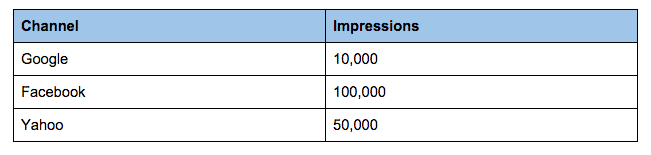
But, because you’re only as good as your data, you might end up with something like this.
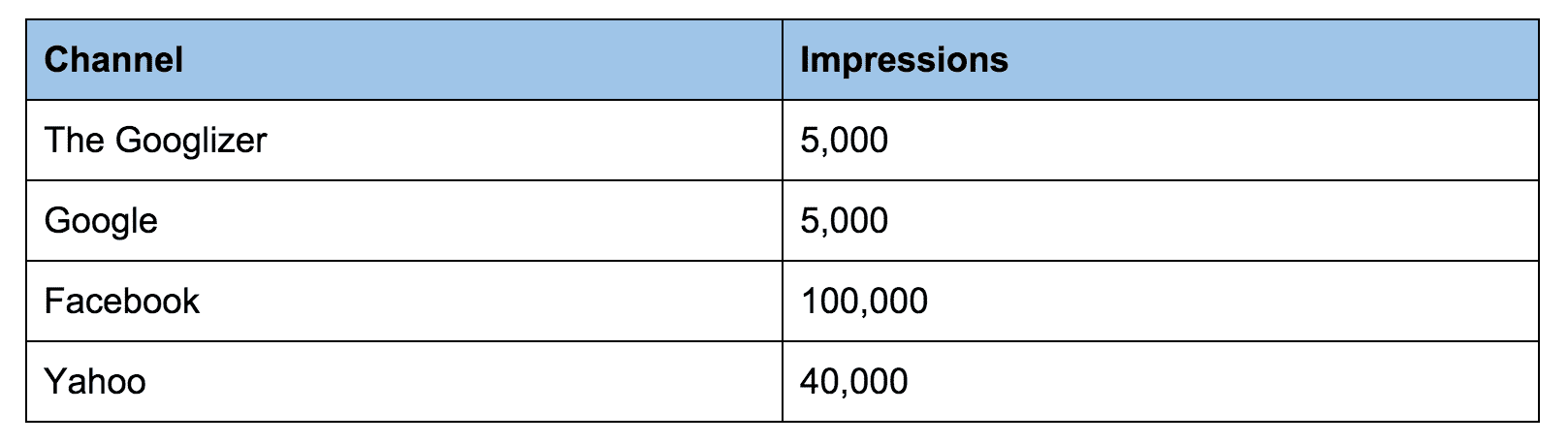
Technically, the same data is there. And based on the context, it’s probably easily recognizable which channels are the same, and it’s probably easy to get to the final steps of the grouping to present the actual results. But, do you see what just happened? We broke off the analysis to think about groupings and slight permutations of words.
Finding and Merging Terms
Because our job is to facilitate the analysis, we’ve been working to develop tools to help find and merge similar terms. This is accomplished in a similar manner that most data science problems are solved: we specify the input data, here two words “google” vs “goooogle”, and we define some similarity metric, here it’s effectively Levenshtein Distance which measures how similar two strings are by counting the number of edits to turn a string into another string. For example, to turn “gooogle” into “google” would require one edit, so the Levenshtein Distance is 1.
By doing this finding and grouping at the data level, we’re enabling the analyst to work with a dataset that has similar terms coalesced into meaningful groups.